
O MongoDB é um banco de dados de código aberto, gratuito, de alta performance, sem esquemas e orientado a documentos lançado em fevereiro de 2009 pela empresa 10gen. Foi escrito na linguagem de programação C++ (o que o torna portável para diferentes sistemas operacionais) e seu desenvolvimento durou quase dois anos, tendo iniciado em 2007.
É utilizado por organizações de todos os tamanhos para a criação de aplicações online onde baixa latência, alta vazão e alta disponibilidade sejam requisitos críticos do sistema. Nele, as informações são armazenadas em documentos BSON, semelhante aos objetos JSON usados largamente na web, ao invés de tabelas e colunas.
No entanto, armazenar dados em documentos é uma forma de persistência relativamente comum entre os banco não-relacionais, sendo o MongoDB o mais popular de todos eles, como mostra o gráfico abaixo da pesquisa mais recente de bancos de dados utilizados pela audiência do StackOverflow em 2017.
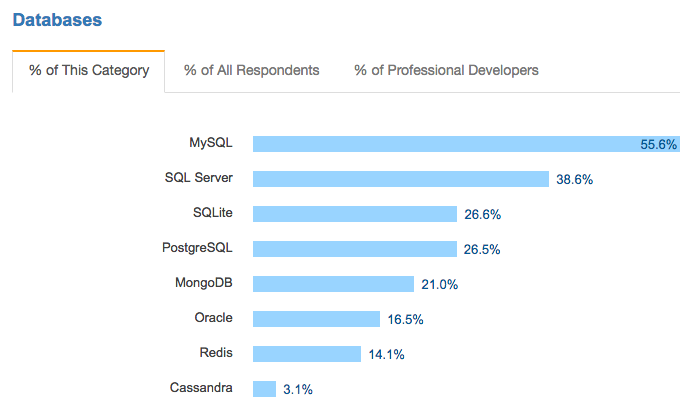
Dentre todos os bancos não relacionais o MongoDB é o mais utilizado – quase ⅕ dos respondentes alegam utilizá-lo em seus projetos, o que é mais até mesmo do que o Oracle, um banco muito mais tradicional.
Até aqui talvez você não tenha lido nenhuma novidade, mas como tirar o maior proveito possível do MongoDB? Como não cair nas armadilhas que se escondem por trás de sua simplicidade? Por que MongoDB e não outro banco de dados?

Essas e outras perguntas serão o tema desse artigo, onde abordarei questões técnicas fundamentadas em cima da documentação oficial do MongoDB e experiências pessoais de dois anos usando esta plataforma de banco de dados.
Esse artigo está organizado em três tópicos:
Você pode ler o post por completo ou apenas estudar o item que mais interessa, clicando sobre ele. Você que manda! ?
#1 Boas práticas de Hardware
Para os desenvolvedores, hardware é algo que não recebe tanta importância (até apresentar problemas!). Não colocar o seu banco MongoDB em um servidor apropriado pode causar muitas dores de cabeça com a tecnologia. É como diz o ditado: o barato sai caro!
Ao contratar serviços em nuvem, como os da Umbler e outros players, procure se informar do tipo de hardware utilizado, como tecnologias de disco e memória, além de dimensionar corretamente a instância de servidor onde estará o MongoDB, é claro. Sobre este último, mais dicas serão apresentadas adiante.
Ah, e não use ambientes compartilhados de MongoDB para aplicações em produção. Nunca! Prefira sempre instâncias e containers dedicados para este serviço ficar executando.
#1.1 Tenha memória RAM suficiente
Como a maioria dos bancos de dados, o MongoDB funciona melhor quando as suas coleções e índices mais utilizados cabem completamente na memória RAM do seu servidor. E, para saber o quanto de RAM cada componente ocupa, use a função stats(). No exemplo abaixo, mostro os stats da coleção ‘customers’:
> db.customers.stats()
{
"size" : 715578011834, // total size (bytes)
"avgObjSize" : 2862, // average size (bytes)
}
Para ter uma noção mais geral, use o comando db.serverStatus() para ver uma estimativa do tamanho do working set atual (dados mais utilizados).
A quantidade de memória RAM é o fator mais importante quando o assunto é hardware. O resultado de outras otimizações nem se compara com a melhoria de performance que ter RAM suficiente proporciona ao seu sistema. Se o seu working set excede a capacidade de memória de um único servidor uma dica é fazer sharding dele em vários servers.
#1.2 Use discos adequados
A maioria dos acessos a dados em bases MongoDB não são sequenciais e, como resultado, são muito mais velozes em discos de acesso aleatório como SSDs, tanto SATA, PCIe e NVMe. Mesmo unidades flash domésticas possuem uma performance superior quando utilizados em uma máquina com boa quantidade de memória RAM (vide dica 1.1) frente aos discos rígidos de alta performance de servidores como SAS e SCSI.
No entanto, enquanto os arquivos de dados beneficiam-se dos SSDs, os arquivos de log do MongoDB são bons candidatos para serem armazenados em discos tradicionais devido ao seu perfil de escrita sequencial, sendo que, quando necessário, o uso de RAID-10 é o mais indicado para a maioria das aplicações.
#1.3 Use múltiplos cores
Pode soar um tanto óbvio, mas o MongoDB realmente opera melhor em ambientes com CPUs rápidas e, especialmente, com a storage engine WiredTiger (a mais recente e recomendada na data que escrevo este artigo), pode-se tirar enorme proveito de multi-cores. Storage engines mais antigas como MMAPv1 não possuem esse mesmo benefício com múltiplos processadores, possuindo aumento de desempenho insignificante em ambientes mais modernos.
O uso de múltiplos cores, aliado ao modelo de concorrência da WiredTiger, fazem com que múltiplas operações concorrentes no seu banco de dados se tornem extremamente mais velozes do que em ambientes single core, na proporção de uma operação concorrente por core.
#2 Boas práticas de aplicação
Ter o ambiente adequado para subir o seu banco de dados é só a primeira etapa rumo a tirar o máximo proveito do MongoDB. Geralmente a construção do ambiente adequado gera um custo direto que nos leva a crer (erroneamente) que é o requisito mais caro de qualquer projeto – quando na verdade não é. A construção correta da aplicação que consumirá o banco de dados muitas vezes é o que consome mais dinheiro a médio e longo prazo, embora seja um custo diluído ao longo do ciclo de vida do projeto.
Neste tópico, vamos ver algumas dicas de uso do MongoDB em suas aplicações, visando a maior performance possível do banco.
#2.1 Atualize apenas os campos alterados
O comando update do MongoDB recebe por padrão o documento JSON, que irá substituir o atual com o mesmo _id usado como filtro, certo? No entanto, substituição de documentos inteiros gera um overhead desnecessário no banco de dados e não é recomendada.
A boa prática aqui é utilizar os operadores de update para alterar somente os campos que de fato foram atualizados pela sua aplicação. Ou seja, se somente o nome do cliente foi editado, envie apenas essa alteração ao banco de dados, diminuindo com isso o tempo de update e o uso de rede.
Relembrando os operadores de update:
- $set: muda o valor de um campo;
- $unset: remove um campo do documento;
- $rename: muda o nome de um campo do documento;
- $inc: quando um campo numérico precisa ser incrementado (ou decrementado, usando um valor negativo);
- $mul: quando um campo numérico precisa ser multiplicado;
Note que como o ACID do MongoDB é garantido somente a nível de documento, um banco com uma concorrência grande pode ter problemas de update caso você opte apenas por utilizar o operador $set (que é o mais simples). Especialmente em campos numéricos que precisem ser alterados, dê preferência aos operadores $inc e $mul, que operarão sobre o valor atual do campo, sem que você tenha de conhecê-lo com antecedência o que poderia causar inconsistências caso o update de outro usuário seja mais veloz no mesmo campo.
#2.2 Evite negações em queries
Como a maioria das bases de dados, o MongoDB não indexa a ausência de valores e condições de negação podem exigir que todos os documentos de uma coleção sejam analisados para dar um retorno à query. Se a negação é a única condição e ela não é seletiva (por exemplo, pesquisar uma coleção de pedidos onde 99% dos pedidos estão finalizados para encontrar aqueles que não estão), todos os registros serão escaneados em busca dos documentos que preencham a negação.
Embora não tenha como você fugir de algumas negações de vez em quando, experimente usar mais os operadores $e, $in e $all do que o operador $ne, sendo o mais seletivo possível se quiser uma performance maior nas consultas. Modelar o banco já pensando nas consultas que irá fazer ajuda bastante, como será discutido no tópico 3.
#2.3 Analise o plano de execução
Para cada query importante da sua aplicação e/ou queries que estejam com mau desempenho, analise o plano de execução da mesma usando a função explain() no final da chamada.
Esta função exibe informações sobre como a query será (ou foi) executada, incluindo:
- Número de documentos retornados;
- Número total de documentos lidos;
- Quais índices foram utilizados;
- Se a consulta foi coberta, ou seja, se ela conseguiu retornar resultados sem ter de ler documentos;
- Se uma ordenação in-memory foi realizada, o que indica que a criação de um índice poderia ser benéfica;
- O número de entradas do índice que foram escaneadas;
- Quanto tempo a consulta levou para retornar, em ms;
- Quais outros planos de execução foram rejeitados pelo motor de consulta do Mongo, indicando ainda o tempo que essa decisão levou, geralmente 0ms (o que indica menos que 1ms)
A ferramenta MongoDB Compass, disponível nas assinaturas Enterprise e Professional do MongoDB, permite visualizar planos de execução de uma maneira bem prática e didática, sendo que cada estágio do pipeline de execução é exibido como um nó em uma árvore, como mostra a figura abaixo:
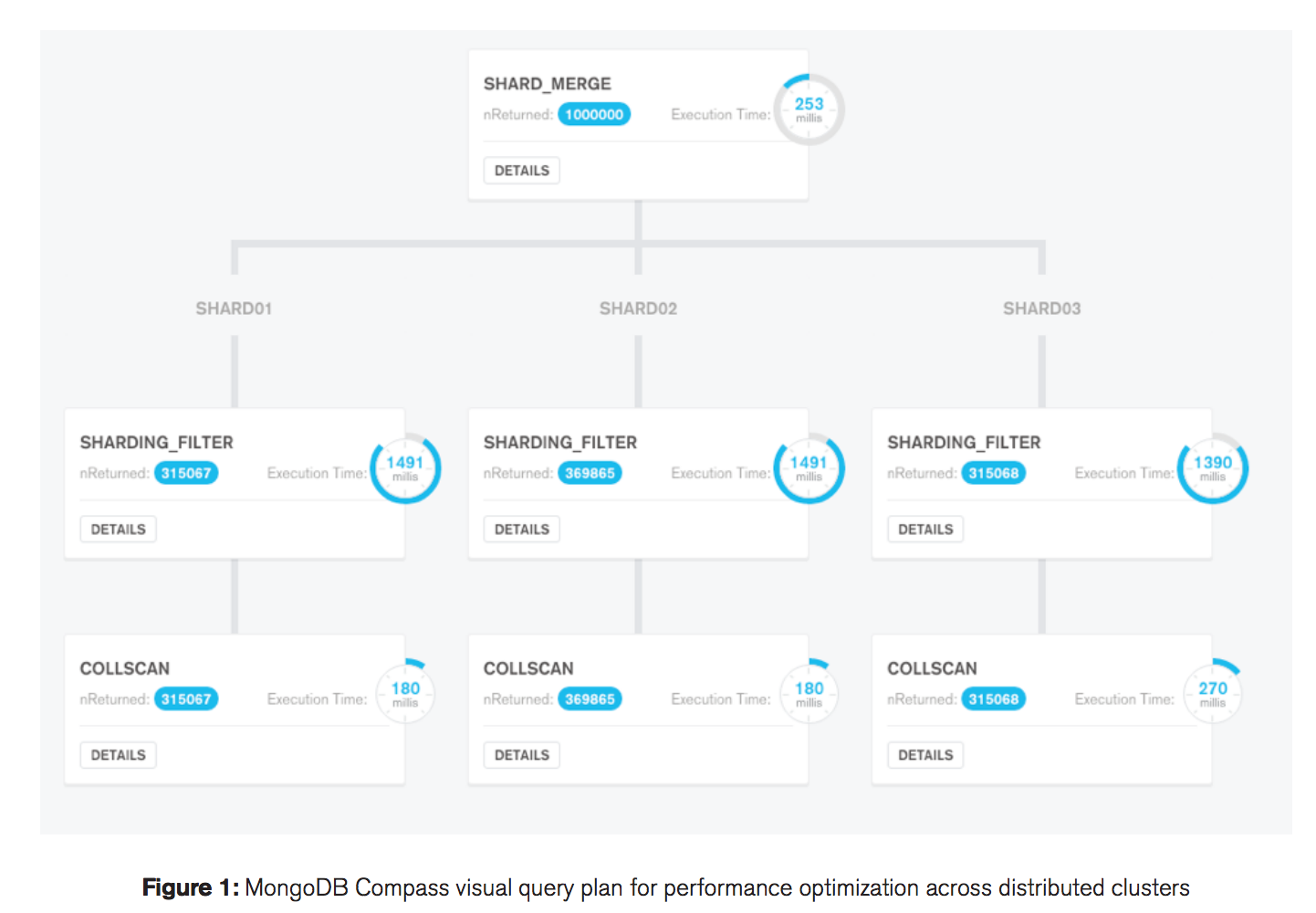
#2.4 Configure a garantia de escrita apropriada
Muito se discute sobre a qualidade da persistência de dados do MongoDB frente aos bancos relacionais mais maduros e líderes de mercado. No entanto, testes e mais testes comprovam que falhas de ACID geralmente são provocadas por má programação, e não pelo banco de dados em si.
Isso porque ao contrário dos bancos relacionais que possuem escrita bloqueante por natureza (e que você pode desabilitar manualmente com NOLOCKs), o MongoDB permite definir o nível de garantia de persistência com o que ele chama de “write concerns”. Essas configurações podem ser realizadas a nível de banco, de coleção, de conexão ou em uma granularidade extremamente fina: a cada operação.
Note que com grandes poderes vem grandes responsabilidades e definir o write concern correto cabe ao analista/arquiteto responsável pela aplicação, sendo que a norma padrão garante apenas performance genérica de escrita, mas que pode não atender ao seu caso específico, considerando a concorrência de leitura e escrita do seu banco.
As opções de write concerns são as seguintes:
- Write Acknowledged: opção padrão e mais veloz. O mongod confirma a execução da operação de escrita dos dados in-memory, permitindo ao cliente detectar rapidamente erros na operação como chaves duplicadas, falhas de comunicação, etc.
- Journal Acknowledged: o mongod confirma a operação somente depois que ela foi registrada no log com sucesso, o que permite que ela sobreviva a uma queda do serviço, garantindo maior durabilidade. Opção mais segura, mas mais lenta.
- Replica Acknowledged: válido apenas quando se está trabalhando com ‘replica sets’. O mongod confirma que o dado não apenas foi escrito no log da réplica primary como nas demais réplicas (você pode configurar de quantas réplicas quer a confirmação).
- Majority: válido apenas para cenários com ‘replica sets’, definindo que a maioria das réplicas também devem confirmar que realizaram a escrita dos dados e dos logs, sempre incluindo a réplica primary.
- Data Center Awareness: mais avançada de todas opções, permite customizar a garantia de escrita em ambientes multi-server.
Caso não lembre como definir essas opções, consulte a documentação oficial do MongoDB, mas a nível de operação. Por exemplo, pode ser feito passando um segundo parâmetro para a função de escrita (insert, nesse caso). Nesse segundo parâmetro você informa um objeto com o tipo de write concern (w:1 é o padrão) e se deve aguardar pela persistência nos logs ou não (j:true).
> db.collection.insert({data}, {w:1, j:true})
#2.5 Use os drivers mais recentes
MongoDB possui drivers de conexão para dezenas de linguagens de programação. Estes drivers são criados pelos mesmos engenheiros que mantém o kernel do banco de dados, mas tendem a ser atualizados de maneira mais constante do que o mesmo, tipicamente a cada dois meses. Sempre use a versão mais recente dos drivers para aproveitar ao máximo a estabilidade, performance e recursos implementados regularmente.
#3 Boas práticas de Modelagem e índices
O MongoDB usa um modelo de dados baseado em documentos binários chamado BSON, que é baseado no padrão JSON. Ao invés das tabelas de uma base relacional, o modelo de dados em documentos do Mongo é fortemente alinhado ao modelo de objetos usado nas linguagens de programação modernas e na maioria dos casos não há a necessidade de transações ou joins complexos devido às vantagens de se ter os dados relacionados ao objeto dentro do próprio objeto (lembra-se de agregação e composição na disciplina de OO e Engenharia de Software?). Note como isso é completamente diferente da divisão em tabelas e os relacionamentos entre elas para compor um objeto na aplicação a partir do banco.
No entanto, mesmo em tese sendo mais fácil de modelar informações em documentos do que em tabelas e relacionamentos, é necessário conhecer algumas boas práticas gerais e ter em mente que o analista/arquiteto do banco de dados é o único que pode realmente dizer qual a melhor abordagem a ser tomada na modelagem e criação de índices para uma aplicação em particular.
#3.1 Armazene todos os dados de uma entidade em um único documento
Existem vários bons motivos para você seguir esta regra, mas vou citar os dois mais importantes: ACID e performance.
O MongoDB garante conformidade com ACID a nível de documento. Se os dados da sua entidade estiverem espalhados entre diversos documentos, não há garantia alguma da consistência e integridade entre eles. Se ele estiver espalhado entre diversas coleções, pior ainda: você corre o risco de perder a atomicidade também.
Além disso, quando os dados do seu registro são armazenados todos dentro de um mesmo documento, você consegue retornar todos os dados do mesmo com uma única consulta por _id no banco de dados, o que é a forma mais eficiente de se retornar dados em qualquer banco. Se pegarmos um exemplo de ecommerce moderno, além do schema instável que os grandes varejistas possuem e que complica a vida dos bancos relacionais, a tela de detalhes de um produto hoje em dia possui muitas informações que podem ser armazenadas juntamente com o produto, tais como:
- reviews do produto;
- versões do produto;
- informações de entrega;
- imagens;
Enquanto que, em um banco relacional, todas essas informações que possuem cardinalidade variável virariam outras tabelas e usaríamos chaves estrangeiras na tabela de produto, no Mongo podemos (e devemos) colocar todas em sub-documentos e campos multi-valorados sem problema algum. E esse é um cenário real e comum mesmo aqui no Brasil, entre os grandes varejistas que já estão utilizando bancos não-relacionais.
No entanto, em alguns casos não é muito prático armazenar todos os dados em um único documento, impactando negativamente em outras operações como updates por exemplo. Lidar com esses trade-offs é responsabilidade do analista/arquiteto da aplicação.
#3.2 Evite documentos muito grandes
Apesar da premissa anterior de salvar todas as informações de um registro no mesmo documento, tenha em mente que o tamanho máximo que o MongoDB suporta para um único documento é 16MB (na data que escrevo este artigo). Na prática, a maioria dos documentos ocupam apenas alguns KB, pois a analogia é a de que um documento seria uma linha na tabela de um relacional – não use documentos como se fossem tabelas inteiras.
Geralmente essa barreira de 16MB é um problema, caso você deseje armazenar binários em conjunto com seus dados, como vídeos e imagens. Neste caso use GridFS, uma convenção implementada por todos os drivers MongoDB que distribuem os binários em documentos menores indexados pelo documento principal.
Embora não seja uma recomendação oficial, não vejo (e nunca vi) muito sentido em armazenar binários no banco de dados, uma vez que você jamais vai consultá-los. Se é apenas para rápido retorno, usar arquivos estáticos na nuvem com CDN é muito rápido atualmente. No entanto, podem existir cenários onde isso é realmente necessário, então tome cuidado com a limitação.
#3.3 Evite nomes de campos desnecessariamente longos
Os documentos BSON são schemaless, ou seja, não existem meta-informações dos documentos salvas em uma tabela de schemas como no caso dos bancos relacionais. Enquanto que isso te torna mais livre para criar documentos com diferenças entre eles e sem uma grande formalização dos dados, isso te cria um grande problema que é o armazenamento dessas meta-informações no próprio documento.
Todos os nomes de campos são armazenados em cada um dos documentos, o que faz com que o consumo de espaço em disco em um banco MongoDB geralmente seja muito maior do que em bancos relacionais, que fazem um uso mais inteligente desse recurso, evitando repetições através de schemas e relacionamentos entre tabelas. Se você tem um milhão de clientes armazenados em documentos, além dos valores dos campos, eles possuem armazenado o nome dos campos.
Uma forma de minimizar esse problema é usar nomes curtos, geralmente apenas as iniciais dos campos e através de programação, fornecer APIs amigáveis para acesso e a manipulação dessas informações nos seus objetos de aplicação (como gets e sets do Java, por exemplo, referenciando os nomes curtos).
Em versões mais recentes do MongoDB, que possuem a storage engine WiredTiger, existe uma compressão automática de nomes grandes para que eles não prejudiquem tanto a performance do sistema.
#3.4 Mantenha a manutenção dos índices em dia
O uso de índices em MongoDB segue os mesmos princípios dos bancos relacionais: melhoram a leitura e prejudicam a escrita dos dados. Sendo assim, caso possua índices que não estão sendo utilizados, remova-os, para garantir que eles não atrapalhem a escolha dos planos de execução pelo motor de consulta do Mongo e principalmente não prejudique a performance de inserts, updates, etc.
Para entender o uso e determinar se um índice merece ou não existir, uma agregação com $indexStats permite saber com que frequência os índices são atualizados, além de algumas ferramentas como MongoDB Compass lhe darem essa informação de maneira rica e visual.
Outra dica é sempre verificar se a sua coleção não deveria ter um índice composto ao invés de vários índices individuais. Caso você possua consultas que sempre usam os mesmos campos, como filtro, e estes campos possuem índices que não são usados individualmente, opte por condensá-los em um único índice composto que será muito mais performático.
Outras dicas gerais
Mais algumas dicas rápidas e muito úteis para quem está começando com MongoDB e não quer cometer alguns erros bem comuns:
- Evite campos multivalorados com muitos elementos, pois a performance em atualizações e inserções vai ficando cada vez mais onerosa. Prefira campos definidos na raiz do documento;
- Evite expressões regulares sem início e/ou fim (ˆ e $, respectivamente), uma vez que os índices são ordenados pelos valores, o que faz com que todo o índice tenha de ser percorrido em expressões regulares ineficientes como essas;
- Scripts complexos do banco de dados devem ser salvos em arquivos .js e versionados junto ao seu projeto da aplicação;
- Na dúvida de como modelar seu banco? Faça-o pensando na experiência de consulta, que é o foco do modelo orientado à documentos;
Estas foram algumas dicas e boas práticas de uso do MongoDB. Embora não existam “verdades universais” quando o assunto são os bancos não-relacionais, as recomendações oficiais são sempre um bom “norte” para quem está começando com tecnologias que não conhecemos bem e é isso que quis trazer aqui hoje, sendo que todas essas dicas (e muitas outras), podem ser encontrados nos artigos técnicos do MongoDB.
Espero que tenham gostado. Se tiver outras dicas ou dúvidas, compartilhe nos comentários!